前言
在执行一条sql的时候,在mysql内部都会通过以下四个流程
+--------------+| 连接器 |+--------------+\|/+--------------+| 分析器 |+--------------+\|/+--------------+| 优化器 |+--------------+\|/+--------------+| 执行器 |+--------------+
我们都知道索引其中一个最主要作用就是加快数据的访问,那么回表、索引覆盖、最左匹配、索引下推 都是mysql的内部优化方式,部分的功能是Mysql5.6的版本上推出的,都是针对索引的优化,如果表中没有索引的情况下,那么就不会有这些优化;
回表
首先我们要知道,每建一个索引在数据库底层都会新建一个B+树,也就是说,一个索引对应一个B+树,回表就是你在查询二级索引字段的时候,二级索引的这棵树中存储的是一级索引的键值,通过这个键值再去一级索引的B+树种查询数据,这种查询叫做回表;
==需要注意的是,只有普通索引才会有回表的情况,如果你不是普通索引的话,是不存在回表的==
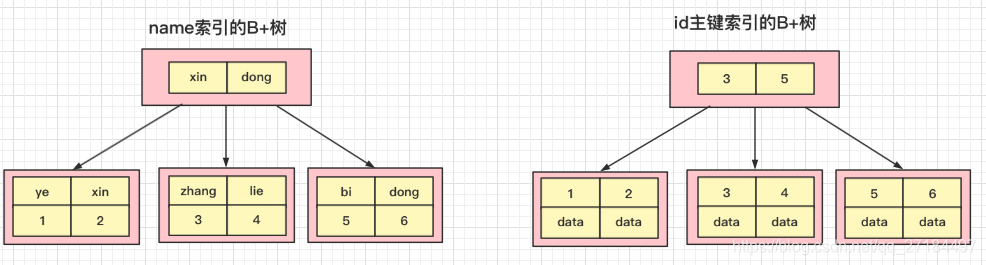
比如我们有一张user表,将id设为主键,将name字段设为普通索引,sql如下
create table (id bigint(20) NOT NULL AUTO_INCREMENT parmary key,name varchar(20) comment '姓名',age int(3) comment '年龄');
sql语句演示
select * from user where name = 'dong'
当数据库在查询上面这条sql时,先去name索引的B+树里面去找对应的字符串dong,叶子节点存储的是对应行的主键id,拿到主键id后再去id索引的B+树找那一行数据,name索引B+树和id主键B+树如下图
覆盖索引
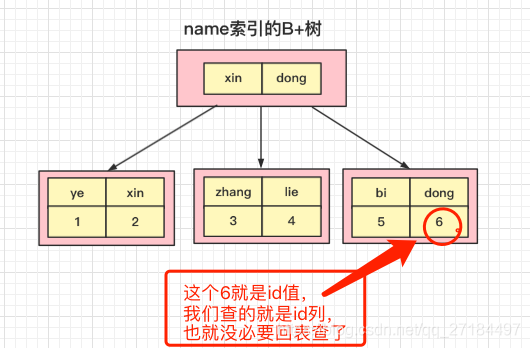
覆盖索引,我们知道索引节点本身其实也是数据,如果我们只需要索引节点数据(只需要索引字段,不需要其他非索引字段),那查询时就可以直接返回索引节点数据,而不需要再回表。
还是这个sql
select id from user where name = 'dong'
因为我们查询列是主键id,name索引的B+树种已经有id的数据了,那我就不需要费那么大劲再去查主键的B+树了,
最左匹配
需要明确一点的是,只有组合索引才会有最左匹配,组合所以的B+树如下图
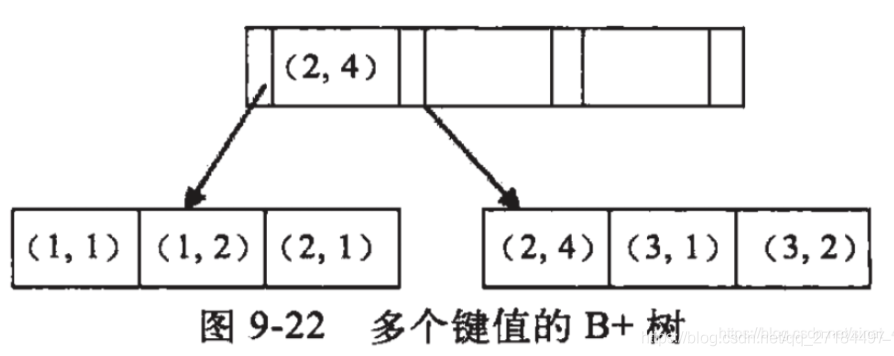
例如我建了个组合索引(a,b,c)。因为A在最左边,如果我只查询where a = ?,那么这种情况也会走索引查询, 这就叫最左匹配
最左匹配还有其他的一些规则,比如当我使用下列sql时索引都会生效
-- where子句几个搜索条件顺序调换不影响查询结果,因为Mysql中有查询优化器,会自动优化查询顺序select * from table_name where a = '1' and b = '2' and c = '3'select * from table_name where b = '2' and a = '1' and c = '3'select * from table_name where c = '3' and b = '2' and a = '1'--都从最左边开始连续匹配,所以下列sql也用到了索引select * from table_name where a = '1'select * from table_name where a = '1' and b = '2'select * from table_name where a = '1' and b = '2' and c = '3'--如果不连续时,只用到了a列的索引,b列和c列都没有用到select * from table_name where a = '1' and c = '3'select * from table_name where a like 'As%'; --前缀都是排好序的,走索引查询select * from table_name where a > 1 and a < 3 -- 可以对最左边的列进行范围查询-- 排序时,只要遵循最左匹配原则都会走索引select * from table_name order by a limit 10;select * from table_name order by a,b limit 10;
下列的sql查询时走的是全表查询(未使用索引)
-- 这些没有从最左边开始,最后查询没有用到索引,用的是全表扫描select * from table_name where b = '2'select * from table_name where c = '3'select * from table_name where b = '1' and c = '3'select * from table_name where a like '%As'//前缀模糊了,走全表查询select * from table_name where a like '%As%'//走全表查询-- 多个列同时进行范围查找时,只有对索引最左边的那个列进行范围查找才用到B+树索引,也就是只有a用到索引,在1<a<3的范围内b是无序的,不能用索引,找到1<a<3的记录后,只能根据条件 b > 1继续逐条过滤select * from table_name where a > 1 and a < 3 and b > 1;select * from table_name order by b,c,a limit 10;// 这种颠倒顺序的没有用到索引
索引下推
索引下推也是只针对联合索引优化,索引下推的优化是为了减少回表次数;因为索引下推是mysql5.6之后才出现的功能,所以我们以下面这条sql为例,分别说明版本5.6之前和5.6之后的区别;
select * from user where name like '张%' and age = 10
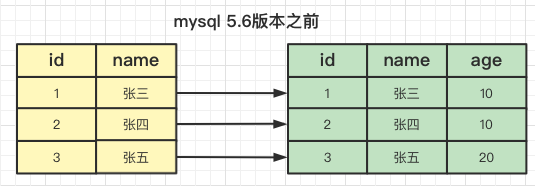
mysql 5.6之前
第一次查询时先找开头为张的name,找到三个id,然后三个id分别回表三次去查询age为10的记录,最后查到2个记录返回给客户端,这是回表次数为3次;
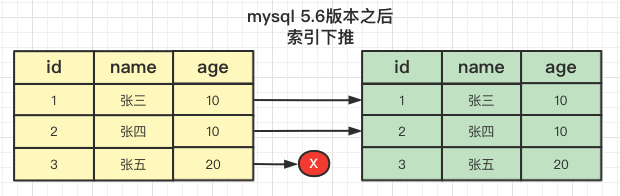
mysql 5.6之后
第一次查询时直接找name字段开头为张,并且InnoDB 在 (name,age) 索引内部就判断了 age 是否等于 10,对于不等于 10 的记录,直接判断并跳过。在我们的这个例子中,只需要对 ID1、ID2 这两条记录回表取数据判断,就只需要回表 2 次
完
mysql 优化在面试时是最常问到的问题,了解这些底层规律有助于我们在回答问题时游刃有余


